7 Key Biochemicals: Amino Acids, Nucleic Acids, and the Genetic Code
Two key classes of chemicals have been seen to operate in all known living things on Earth: amino acids and nucleic acids. Amino acids are the fundamental building blocks of proteins, which are essential for most biological processes. Nucleic acids make up the genetic code of all living things on Earth. Here, we investigate the chemistry and interplay between these crucial chemicals.
Learning Objectives
By the end of this chapter, you will be able to:
- Explain the structure of amino acids and proteins
- Discuss the importance of proteins for the functioning of life
- Describe the basic features of DNA and RNA and their components
- Discuss the role of an organism’s genetic code and the impact of genetic mutations
Amino Acids to Proteins
Amino acids and the proteins they combine to form are found in every living organism on Earth. Proteins are needed to make critical biological reactions happen on timescales relevant to life. Proteins regulate the processes that drive life. Though proteins are found across all living things and carry out a wide variety of roles, every protein on Earth is made up of only twenty different amino acids.
Amino Acids
Amino acids are molecules that are defined by a specific structure; all amino acids consist of a central carbon atom forming four bonds to: (1) a hydrogen atom, (2) an amino group (-NH2), (3) a carboxyl group (-COOH), and (4) a changeable side chain (see Figure 1 below). In organic chemistry, molecules with a carboxyl group are called carboxylic acids. This along with the amino group gives these compounds the name amino acid.

The amino and carboxyl groups allow amino acids to bond to one another through a process of dehydration, i.e. a process that releases water (H2O). Figure 2 below diagrams the reaction with structural formulas. Water is formed by the loss of an -OH group and a hydrogen (H) atom.
This process forms a new bond, called a peptide bond, between the carbon and nitrogen atoms. Chains of amino acids are joined by peptide bonds; these chains are therefore also called polypeptide chains. Figure 3 shows an example of a polypeptide chain. Polypeptide chains are then folded into proteins. Note that Figure 3 uses a mixture of a structural and molecular formula; specifically, not all bonds to Hydrogen atoms are shown with a line.


The side chains give each amino acid a unique functionality. Examples of amino acids and their side chains are shown in Figure 3 in green. Amino acids can be positively or negatively charged, water-repellent, bulky, bent into different configurations, or have other properties depending on their side chains. These differences help the polypeptides fold as they form proteins, bind to specific compounds, or chemically react in different ways.
Despite the fact that more than 500 amino acids exist on Earth, living things on Earth incorporate only 20 different amino acids to form the vast array of proteins that are used to regulate chemical reactions in all aspects of life. This is similar in spirit to the concept that even though the English languages only uses 26 letters, those same letters make up the words that compose millions of books.
Want to know more: Essential Amino Acids, Body Building, and You
Of the 20 amino acids used by life on Earth, the human body is capable of synthesizing all but nine. These nine amino acids are known as the essential amino acids. It is important to include sources of these amino acids either from meat or plants in a healthy diet since the body has no other source for them.
In fact, many products sell amino acids as supplements targeted towards endurance athletes and body builders. Scientists have been able to trace different amino acids and the role they play in muscle contraction or recovery to identify what the body needs after the coach has said “last set'” for the third set in a row. For example, glutamine is drained during intense physical activity. If the body’s glutamine stores become depleted, the body begins to break down muscle cells to compensate.
Proteins
It is commonly said that you are what you eat, but perhaps more correctly, you are what your proteins decide to do. Proteins are the driving force behind the processes of life. Many proteins act as enzymes, which are highly specified molecules that allow complicated organic reactions to progress more easily.
In most organic reactions, the molecules involved must first assume an unfavorable, intermediate configuration (see Figure 5 below) before progressing to the finished product. Enzymes bind to these starting molecules and act to stabilize the intermediary state. This makes it easier for molecules to progress to the desired final products. Enzymes are the primary why to increase reaction rates for biochemical processes.
")
In addition to acting as enzymes, proteins also fulfill several other important roles. Proteins are involved with cell signaling, which helps different cells in the body work together. Antibodies are proteins that work with the body’s immune system to recognize and destroy foreign substances that might cause illness. Structural proteins give shape or rigidity to cells, such as those that make up our nails or hair. Motor proteins allow for the movement of single-celled organisms. In short, proteins are critical for all of the basic functions of life.
Chirality of Amino Acids and Proteins
The central carbon in an amino acid can serve as a chiral center because it is typically bound to four different groups. Recall that chirality is defined as the property of an object that can not be superimposed on its mirror image, like how your palm-up hands cannot lay exactly on one another. The one exception is the amino acid, glycine, whose hydrogen side chain makes it a symmetric molecule.
The chirality of amino acids means there exists both left-handed and right-handed amino acids (Figure 6 below). Oddly, while either configuration is possible, life on Earth only uses left-handed amino acids.

Studies have been done to investigate how the chirality of protein affects how it is made and performs. Synthesis of both left-handed and right-handed amino acids is not only possible, it is chemically equivalent. From an energy standpoint, protein that is composed entirely of right-handed amino acids should function just as well as proteins made of left-handed amino acids. The only difference is that using only one type of chirality could add an extra layer of regulation in biochemical reactions that may help to reduce synthesis errors.
How did life come to pick left-handed proteins over right-handed ones? There are many competing theories as to the origins of this inequality. One idea is that left-handed amino acids are slightly more water soluble (i.e., easier to dissolve in water), which could have made them easier to incorporate into early life. Amino acids may also have been affected by the polarization of light.
Want to know more: Polarization
The polarization of light defines how the wave component of light oscillates relative to the direction in which the light is moving. Figure 7 shows light traveling from the bottom-right corner to the top-left corner. It shows how the polarization of light can be (1) incoherent, as in the right-most third of Figure 7, (2) oscillate back and forth in only one direction, i.e., linearly polarized as in the center of Figure 7, or (3) circularly polarized as is shown in the first third of Figure 7. Different types of filters (shown in Figure 7 as blue squares) help give rise to these types of polarization. In the early Solar System, it is thought that dust grains could have caused all light to be circularly polarized.

It is possible that this circularly polarized light might have been more damaging to right-handed amino acids or more favorable to left-handed ones. Amino acids found in space, for example on meteorites, also exhibit an excess of left-handed molecules. If polarized sunlight gave rise to this imbalance, it could have tipped the scales to the left for life on Earth. Regardless of what established the original inequality, biological processes probably accentuated the imbalance.
Nucleic Acids to Genes
Nucleic acids are used throughout life on Earth to transfer genetic information during cell replication. This genetic information defines the nature and structure of organisms.
Genes that are shared through cell replication and reproduction is why offspring look like their parents. Differences in genetic information can give rise to differences in the traits of an organism. For example, a change in genetic information may result an organism that is taller/shorter or fur color that is lighter/darker.
The process of gene replication—specifically gene mutation, which describes the errors that occur during gene replication—allow for different traits to arise. Some traits may allow an organism to survive better in a given environment. Lighter fur may be useful to blend in with a snowy environment; darker fur may be more helpful in a dark forest.
Organisms with these advantageous traits are more likely to be able to reproduce and pass on their favorable traits. This process of natural selection allows organisms to adapt and evolve to different environments. This ability to grow better equipped to surviving in an environment, also known as Darwinian evolution, is thought to be a key aspect of all living things.
Nucleotides
The nucleic acids found in all known living things on Earth take two forms: ribonucleic acid (RNA) and deoxyribonucleic acid (DNA). Nucleic acids are long, complex chains made up of nucleotides, a specific kind of molecule as diagramed in Figure 8. Nucleotides consist of three components: (1) a central sugar, (2) an interchangeable base, and (3) a phosphate group.
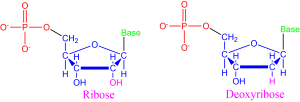
RNA and DNA differ by the central sugar of the nucleotides that makes them up. RNA uses ribose sugar while DNA uses deoxyribose sugar, which has one less oxygen molecule (note the atoms bonded to the 2nd carbon atom of each nucleotide shown in Figure 8).
The base of a nucleotide changes depending on the specific nucleotide, much like how different amino acids have different side chains. In living things on Earth, five different bases are used. RNA uses adenine, cytosine, guanine, and uracil (ACGU). DNA also uses adenine, cytosine and guanine, but uses thymine in place of uracil (ACGT). These bases bond to each other in specified ways. Cytosine always binds to guanine. Adenine bonds to the thymine in DNA and the uracil in RNA.
The structural formula for the five different bases are drawn in Figure 9. Nucleotide bases fall into two categories: double-ringed purines (A,G) and single-ring pyrimidines (C, T, U). Some of these bases were named after the material where they were first discovered. For instance, guanine was first discovered from guano, a fancy name for bird poop.

A phosphate group consists of a phosphorus atom bound to four oxygen atoms. This configuration contains many high energy bonds. The energy stored in this phosphate group allows nucelotides to undergo the reaction that links nucleotides together to form the long-chain nucleic acids that are RNA and DNA. These nucleic acids have a specific structure that was revealed only in the 1950s.
Want to know more: ATP – Cellular Energy Banks
An influx of energy is required to carry out many of the processes necessary for life. You eat to enable your body to create stores of energy to use for these reactions. You eat to create adenosine triphosphate, or ATP.
ATP, shown in Figure 10, is the most widely used energy carrier in all living organisms on Earth. ATP is also a nucleotide consisting of (1) a ribose sugar, (2) an adenine base, and (3) three phosphate groups bonded in a chain. When energy is needed for a chemical reaction, one of the high-energy phosphate to oxygen bonds in the chain is broken. This converts ATP to ADP, adenosine diphosphate, where only two phosphate groups remain.
Phosphate groups are used across living organisms on Earth to supply the energy for necessary reactions. Can you think of reasons why having a common source of energy across reactions would be beneficial? (Hint: would you rather have different charging cables for each of your devices, or one common charging cable?)

How do we know: DNA’s structure
The exact structure of DNA was revealed through a series of insights that built on one another. When DNA was broken up into its constituent nucleotides, it was discovered that certain bases always appeared in the same proportions. The number of adenine and thymine nucleotides was always equal, and the number of cytosine nucleotides was always equal to the number of guanine nucleotides. In 1949, Erwin Chargoff, an Austro-Hungarian-born American biochemist, sought to explain this observation with the idea of base pairing—the idea that in DNA adenine is always bonded to thymine and cytosine is always bonded to guanine.
Observations of DNA using x-ray crystallography further revealed the structure of the molecule. X-ray crystallography is a complicated technique akin to shining a flashlight into a hall of mirrors and determining where the mirrors are placed based on the way that the light bounces around.
Rosalind Franklin, a British chemist, had a background in physical chemistry that she used to improved on x-ray crystallography techniques in the mid 1900s. Franklin produced unprecedentedly precise x-ray crystallography images (see Figure 11) while working in the lab of Maurice Wilkins. Her most famous photo, known as “Photo 51”, held the key to DNA’s structure. This photo was heralded by J.D. Bernal, the father of x-ray crystallography in biochemistry, as “among the most beautiful x-ray photographs of any substance ever taken.

The theoretical biochemists James Watson and Francis Crick used the idea of base pairing and Franklin’s images to reveal the double-helix structure of DNA. Watson discovered that the adenine-thymine bond was exactly the same length as the cytosine-guanine bond, which helped him form the picture of each base pair as rungs of a ladder. Crick helped to develop a mathematical model for the pattern that a helical structure would produce with x-ray crystallography.
In 1951, Crick and Watson began to work together. When Maurice Wilkins showed them Rosalind Franklin’s Photo 51, they were able to piece together the double-helix model of DNA (see Figure 12).

The double-helix backbone of DNA is composed of the sugar and phosphate components of nucleotides. The bases stick out from this backbone and bind to their appropriate counterpart through weak hydrogen bonds. In the most common form, the bases appear parallel to each other, like a well-designed stairwell. The double-stranded nature of DNA affords a rigid, stable, and long-lived structure. During DNA replication, each strand is checked against the other to reduce copying errors or accidental mutations.
Translating the Genetic Code
The genetic code in DNA is translated into instructions for how to manufacture proteins with the help of RNA. Messenger RNA (mRNA) transcribes the code from where DNA is located in the cell and carries this information to the ribosome. Ribosomes are the molecules responsible for fabricating proteins in a cell.
A ribosome can read the genetic code from mRNA and translate it to the necessary amino acids to build a protein. Ribosomes themselves are made up in part of RNA, known as ribosomal RNA (rRNA). Each amino acid is specified by different codons, a sequence of three base pairs. Transfer RNA (tRNA) matches up each codon with the appropriate amino acid. These different amino acids are bonded together into a polypeptide chain that can then be folded into the needed proteins.

The Genetic Code
DNA encodes and stores genes, which describe a unit of genetic information. Together, all the genes stored in DNA provide a very lengthy instruction manual for all living creatures on Earth. If you took the entire chain of DNA in one human cell and completely stretched it out, it would measure roughly 2 meters, the average height of an NBA player. If you took all of the DNA from all of the cells in a human body and joined them end-to-end, they would cross the diameter of the Solar System twice.
Different segments of DNA are known as chromosomes. An organism’s genome is the complete collection of chromosomes. Humans have 23 pairs of chromosomes, encoding roughly 25,000 genes using about 3 billion base pairs. A mosaic of the entire human genome was sequenced between 1990 and 2008. This monumental effort brought together twenty different institutions in six different countries. This remains one of the most impressive collaborative projects in science.
Want to know more: My, What Big Genomes You Have
All the better to encode with…or is it? Intuitively, it might seem that a larger genome would correspond to more complex organisms. A larger genome would allow for more genes, meaning more genetic traits, meaning more complexity. This is wrong.
An example of different genome sizes is given by the table below. Various species are ordered by increasing genome size as defined by the number of base pairs in the organism’s complete genome.
| Species | Base Pairs | Genes |
| Virus | 170,000 | ? |
| E. Coli | 4,600,000 | 3,200 |
| Fruit Fly | 180,000,000 | 13,600 |
| Chicken | 1,000,000,000 | 23,000 |
| Corn | 2,500,000,000 | 59,000 |
| Human | 3,000,000,000 | 25,000 |
| Lily | 100,000,000,000 | ? |
| Grasshopper | 180,000,000,000 | ? |
| Amoeba | 670,000,000,000 | ? |
Not only does genome size not scale with perceived organism complexity, it also does not scale with the number of genes. Humans have longer genomes than chickens, but we lose out to grasshoppers. Humans also have a longer genome than corn, but less genes.
One reason for this is that most DNA is noncoding DNA, which does not translate directly to genes. Noncoding DNA may instead be used to signal the start of a gene, to help with DNA coiling, and/or potentially carry out several other functions that we have yet to discover.
Remarkably, more than 98% of the human genome is non-coding. In contrast, only 20% of the DNA in bacteria is noncoding DNA. The bladderwort plant currently holds the record for most efficient genome with only 3% noncoding DNA.
DNA encodes important instructions for life, but it can become damaged when base pairs or whole segments of DNA are deleted, inverted, duplicated, or moved around. Mutations can be damaging, for example, causing cells to become cancerous. Damage sustained to the phosphate-sugar backbone of DNA is one of the primary causes of mutations. This type of damage is a common result of exposure to UV radiation, such as from the Sun (never skimp on sunscreen).
However, mutations can also occur naturally, resulting in expressed altered genes that give rise to new characteristics. This is the mechanism for Darwinian evolution: beneficial traits arising from mutation will be preferentially selected when mating and propagated through succeeding generations.
Natural mutations arise at measurable rates for different species. This mutation rate allows us to measure the genetic distance between species. This value is obtained by determining the statistical number of mutations required to change one species’ genome into another’s. For example, deer and giraffes are close in genetic difference, the genome of a deer requires relatively few differences to change into the genome of a giraffe when compared to, say, the genome of sunflowers.
Concept Check
Key Concepts and Summary
Two classes of molecules are common to every form of life on Earth: amino acids and nucleic bases. Understanding the fundamental and relatively simple structure of these molecules allows us to see the more complex patterns of biochemistry. Amino acids are the units for building proteins. While there are hundreds of possible amino acid chains, life on Earth uses only a common set of twenty and some amino acids have been detected with radio telescopes in giant molecular clouds – the star-forming regions of space. The nucleic bases adenine, guanine, thymine and cytosine are components of DNA (and in RNA with a substitute of uracil for thymine). In addition to nucleic bases, the nucleotides in RNA and DNA contain a central sugar and a phosphate group. DNA encodes the genetic information for every organism in a collection of chromosomes. DNA transcription errors result in mutations that occur naturally, but the mutation rate can increase with exposure to ultraviolet light or carcinogenic chemicals.
Review Questions
Exercises
- It is fairly easy to extract DNA from a strawberry using household materials. See the step-by-step instructions here. In a formal laboratory setting or on your own, follow the steps to extract DNA and take detailed notes of the challenges or successes in your endeavor. What do you observe about the characteristics of the DNA you extracted?
Summary Questions
- What is an amino acid and how do amino acids form proteins?
- What functions do proteins have in living things?
- What is a nucleic acid? How do the two main nucleic acids used by life, RNA and DNA differ?
- What is the chemical structure of DNA?
- How are nucleic acids and genes related?
- What causes genetic mutations?
