Chapter 5: Attention
5.3. Preattentive Vision
Our visual system also processes information through multiple stages, from rapid automatic processing to detailed conscious analysis. Understanding these stages helps explain how we make sense of complex visual scenes so quickly and efficiently.
Pre-attentive Vision
Before we consciously focus on any part of a scene, our visual system automatically processes certain basic information. This pre-attentive processing occurs rapidly and in parallel across the entire visual field, requiring no conscious effort. Research has shown that this automatic processing helps us:
- Detect basic features like color, orientation, and movement
- Process multiple elements simultaneously
- Guide our attention to potentially important areas
- Operate efficiently without consuming attentional resources (Wolfe & Utochkin, 2019)
Scene Gist
Within a fraction of a second (around 100 milliseconds), we can extract the essential meaning or “gist” of a scene. This rapid scene recognition allows us to:
- Categorize environments (indoor vs. outdoor)
- Identify basic elements (animals, people, vehicles)
- Recognize broad spatial layouts (open spaces vs. enclosed areas)
- Detect general geometric properties
This remarkable ability operates even before we direct our attention to specific details, helping us quickly understand our environment and decide where to focus our attention next.
Bottom-up Salience
Visual salience refers to how much certain elements in a scene naturally “pop out” or grab our attention. This process is driven by basic visual properties rather than our conscious goals or expectations. Elements become salient when they differ significantly from their surroundings in terms of:
- Color
- Orientation
- Size
- Movement
- Brightness
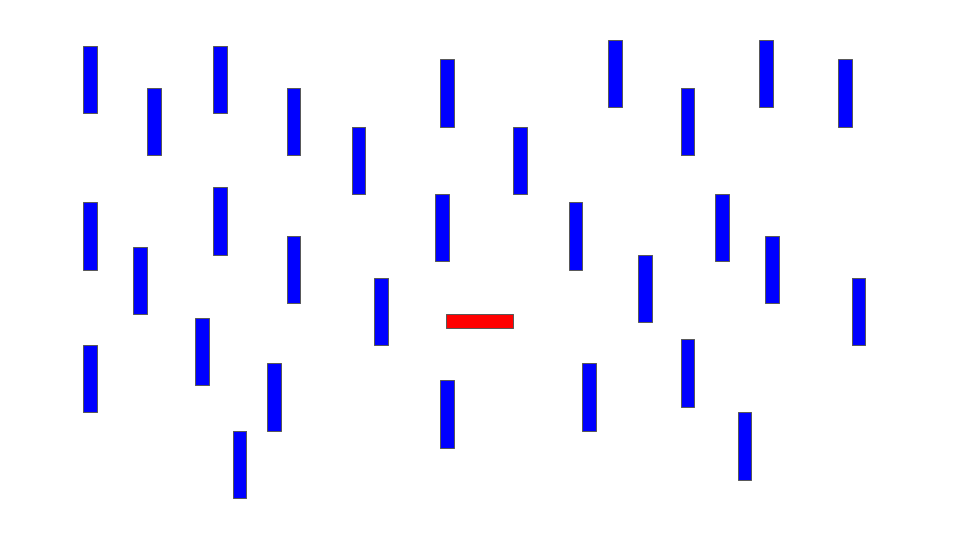
As shown in Figure 5.3, an object that differs markedly from its surroundings in orientation or color automatically captures our attention. This bottom-up processing helps us quickly identify potentially important elements in our environment.
The Interaction of Bottom-up and Top-down Processing
Our visual exploration of scenes involves a sophisticated interplay between automatic and conscious processes. Eye movement detectors (eye trackers) are often used to track attention. They measure both rapid eye movements which are called saccades and fixations (the places in the visual field when the eyes are still). Thus, we can measure where people look first when viewing a picture and where they look the most. Figure 5.4 shows a visual scan path from an eye tracker. We can see that most of the fixations are around the eyes and most saccades are between the eyes and the nose and the mouth.

Initial Saccades
The first saccade we make when viewing a new scene is primarily driven by bottom-up salience – we automatically look at things that stand out visually.
Subsequent Saccades
After the initial glance, our eye movements become influenced by both:
- Bottom-up factors (visual salience)
- Top-down factors (our goals, expectations, and prior knowledge)
For example, if you’re looking for your friend in a crowd, your visual search will be guided both by visually distinctive features (someone waving) and your knowledge of what your friend looks like and typically wears. This combination of rapid, automatic processing and goal-directed attention allows us to efficiently process complex visual scenes while focusing on the information most relevant to our current needs.
