Chapter 11: Hearing in Complex Environments
11.6. Understanding Speech
Understanding speech has many challenges as exemplified by the difficulty that many of us have when using computerized speech recognition software when we are calling a helpline for information. There are several issues that contribute to the difficulties. Firstly, people vary a lot in terms of how they speak, i.e., their accent, how quickly they speak, and how much they articulate. Our brain analyzes the indexical characteristics of a person’s voice to make assumptions about their age, gender, and where they come from. Another issue is that it is difficult to know where one phoneme or word ends and another begins. People who study speech call this the segmentation problem.
SEGMENTATION PROBLEM
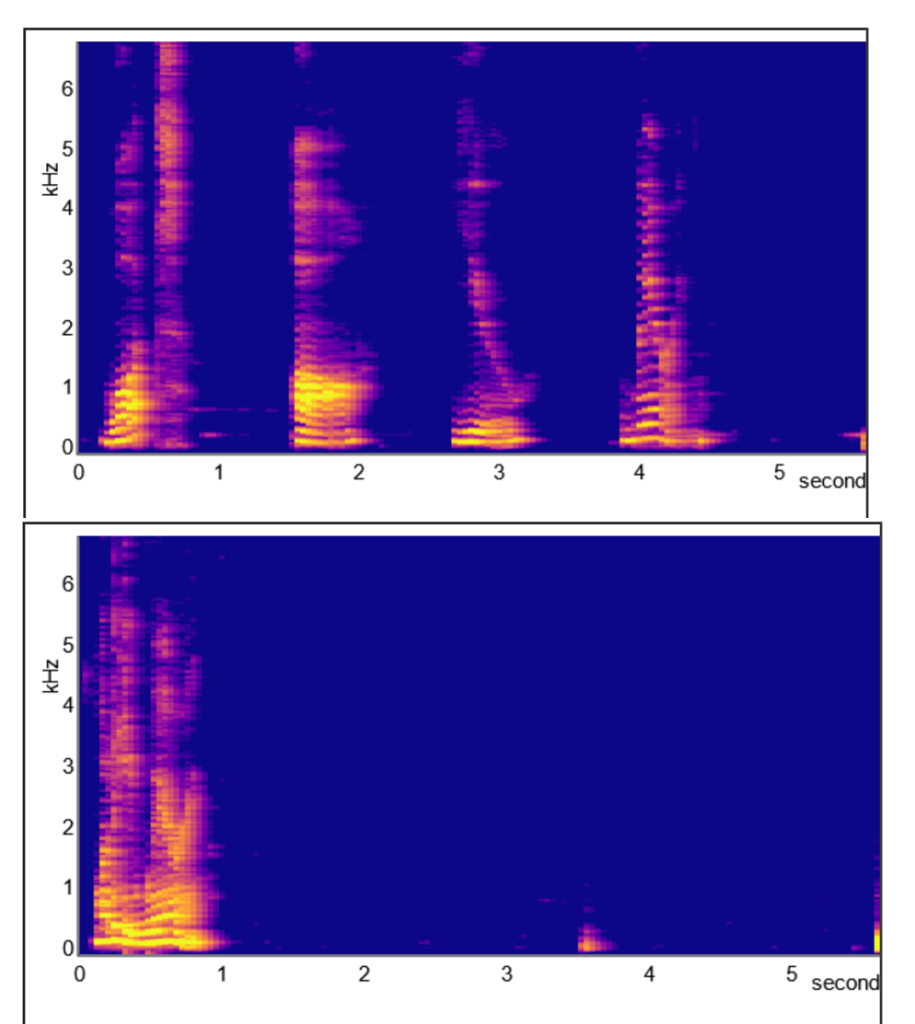
We can see evidence for the the segmentation problem when we look at the spectrograms in Figure 11.8 for two different sentences. The top spectogram is unusual in that the person is pausing between each word and we see clear gaps between the words – What are you wearing? In contrast, in the bottom spectogram, the person is talking more naturally and says “Whaddya wearin’? It is impossible to see any segmentation between the words. You can create your own spectograms at this website: https://auditoryneuroscience.com/acoustics/spectrogram
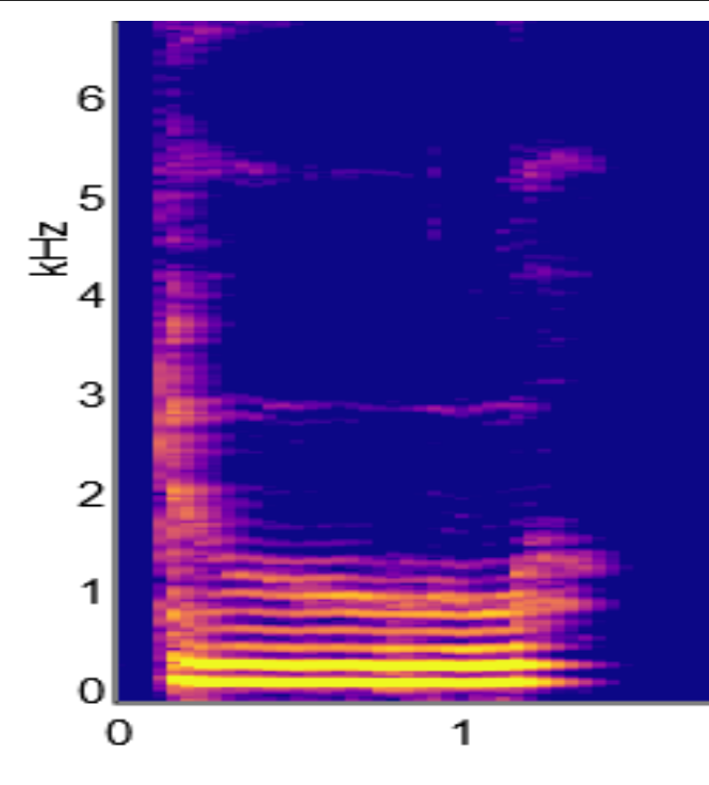
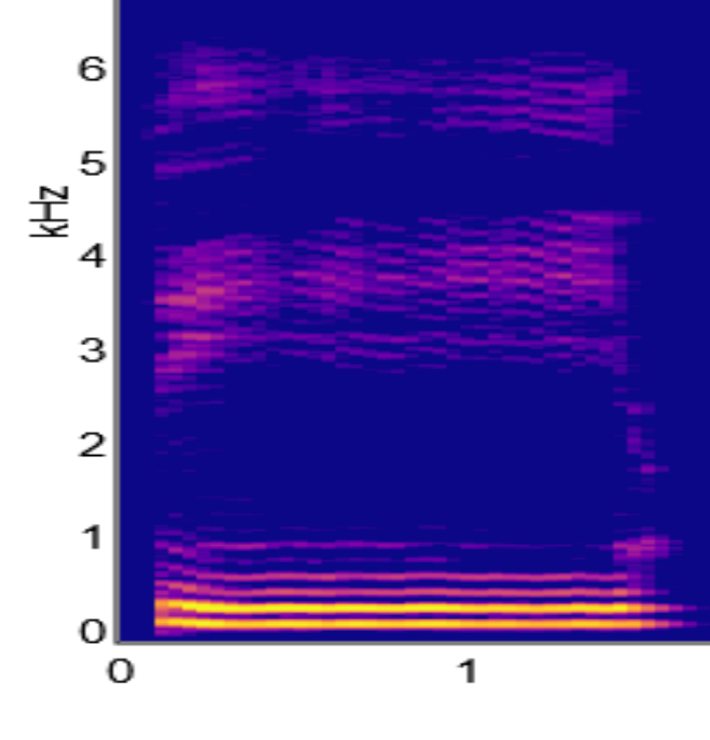
COARTICULATION PROBLEM
Another contributor to variability in speech is the coarticulation problem. Consonant transitions look different depending on the vowel that they precede. Take for example, the difference in the spectograms for two phonemes, du and di. Although to our ears, the “d” sound is the same for both phonemes, when we look at the formant transitions for the 3 Hz formant in the spectrograms for du (Figure 11.9) versus di (Figure 11.10) we see that they are going in different directions. Clearly, the sound reaching our ears is quite different. If you look at someone’s mouth when they say du versus di, it is clear they have to change the shape of their mouth before they make any sound. Getting ready to make an du sound requires a different mouth shape to di. So, we have to take into account both the consonant and the vowel, i.e., we need to combine or coarticulate two sounds. This explains why we have the coarticulation problem.
So why are humans so much better than computers at figuring out what other people are saying? Human listeners employ a lot of social and contextual cues (e.g., visual cues) to figure out what people are saying. Computers do not have access to this information. We frequently use lipreading to help us intepret what we are hearing. The McGurk effect shows how we use visual cues to help figure out which phoneme is which. In other words, what we see affects what we hear.
To learn more about the McGurk Effect, watch the video linked here and included below.
Cheryl Olman PSY 3031 Detailed Outline
Provided by: University of Minnesota
Download for free at http://vision.psych.umn.edu/users/caolman/courses/PSY3031/
License of original source: CC Attribution 4.0
