Module 10: Inference for Means
Hypothesis Test for a Population Mean (1 of 5)
Hypothesis Test for a Population Mean (1 of 5)
Learning outcomes
- Recognize when to use a hypothesis test or a confidence interval to draw a conclusion about a population mean.
- Under appropriate conditions, conduct a hypothesis test about a population mean. State a conclusion in context.
Introduction
In Inference for Means, our focus is on inference when the variable is quantitative, so the parameters and statistics are means. In “Estimating a Population Mean,” we learned how to use a sample mean to calculate a confidence interval. The confidence interval estimates a population mean. In “Hypothesis Test for a Population Mean,” we learn to use a sample mean to test a hypothesis about a population mean.
We did hypothesis tests in earlier modules. In Inference for One Proportion, each claim involved a single population proportion. In Inference for Two Proportions, the claim was a statement about a treatment effect or a difference in population proportions. In “Hypothesis Test for a Population Mean,” the claims are statements about a population mean. But we will see that the steps and the logic of the hypothesis test are the same. Before we get into the details, let’s practice identifying research questions and studies that involve a population mean.
Try It
Example
Cell Phone Data
Cell phones and cell phone plans can be very expensive, so consumers must think carefully when choosing a cell phone and service. This decision is as much about choosing the right cellular company as it is about choosing the right phone. Many people use the data/Internet capabilities of a phone as much as, if not more than, they use voice capability. The data service of a cell company is therefore an important factor in this decision. In the following example, a student named Melanie from Los Angeles applies what she learned in her statistics class to help her make a decision about buying a data plan for her smartphone.
Melanie read an advertisement from the Cell Phone Giants (CPG, for short, and yes, we’re using a fictitious company name) that she thinks is too good to be true. The CPG ad states that customers in Los Angeles get average data download speeds of 4 Mbps. With this speed, the ad claims, it takes, on average, only 12 seconds to download a typical 3-minute song from iTunes.
Only 12 seconds on average to download a 3-minute song from iTunes! Melanie has her doubts about this claim, so she gathers data to test it. She asks a friend who uses the CPG plan to download a song, and it takes 13 seconds to download a 3-minute song using the CPG network. Melanie decides to gather more evidence. She uses her friend’s phone and times the download of the same 3-minute song from various locations in Los Angeles. She gets a mean download time of 13.5 seconds for her sample of downloads.
What can Melanie conclude? Her sample has a mean download time that is greater than 12 seconds. Isn’t this evidence that the CPG claim is wrong? Why is a hypothesis test necessary? Isn’t the conclusion clear?
Let’s review the reason Melanie needs to do a hypothesis test before she can reach a conclusion.
Why should Melanie do a hypothesis test?
Melanie’s data (with a mean of 13.5 seconds) suggest that the average download time overall is greater than the 12 seconds claimed by the manufacturer. But wait. We know that samples will vary. If the CPG claim is correct, we don’t expect all samples to have a mean download time exactly equal to 12 seconds. There will be variability in the sample means. But if the overall average download time is 12 seconds, how much variability in sample means do we expect to see? We need to determine if the difference Melanie observed can be explained by chance.
We have to judge Melanie’s data against random samples that come from a population with a mean of 12. For this reason, we must do a simulation or use a mathematical model to examine the sampling distribution of sample means. Based on the sampling distribution, we ask, Is it likely that the samples will have mean download times that are greater than 13.5 seconds if the overall mean is 12 seconds? This probability (the P-value) determines whether Melanie’s data provides convincing evidence against the CPG claim.
Now let’s do the hypothesis test.
Step 1: Determine the hypotheses.
As always, hypotheses come from the research question. The null hypothesis is a hypothesis that the population mean equals a specific value. The alternative hypothesis reflects our claim. The alternative hypothesis says the population mean is “greater than” or “less than” or “not equal to” the value we assume is true in the null hypothesis.
Melanie’s hypotheses:
- H0: It takes 12 seconds on average to download Melanie’s song from iTunes with the CPG network in Los Angeles.
- Ha: It takes more than 12 seconds on average to download Melanie’s song from iTunes using the CPG network in Los Angeles.
We can write the hypotheses in terms of µ. When we do so, we should always define µ. Here μ = the average number of seconds it takes to download Melanie’s song on the CPG network in Los Angeles.
- H0: μ = 12
- Ha: μ > 12
Step 2: Collect the data.
To conduct a hypothesis test, Melanie knows she has to use a t-model of the sampling distribution. She thinks ahead to the conditions required, which helps her collect a useful sample.
Recall the conditions for use of a t-model.
- There is no reason to think the download times are normally distributed (they might be, but this isn’t something Melanie could know for sure). So the sample has to be large (more than 30).
- The sample has to be random. Melanie decides to use one phone but randomly selects days, times, and locations in Los Angeles.
Melanie collects a random sample of 45 downloads by using her friend’s phone to download her song from iTunes according to the randomly selected days, times, and locations.
Melanie’s sample of size 45 downloads has an average download time of 13.5 seconds. The standard deviation for the sample is 3.2 seconds. Now Melanie needs to determine how unlikely this data is if CPG’s claim is actually true.
Step 3: Assess the evidence.
Assuming the average download time for Melanie’s song is really 12 seconds, what is the probability that 45 random downloads of this song will have a mean of 13.5 seconds or more?
This is a question about sampling variability. Melanie must determine the standard error. She knows the standard error of random sample means is [latex]\sigma/\sqrt{n}[/latex]. Since she has no way of knowing the population standard deviation, σ, Melanie uses the sample standard deviation, s = 3.2, as an approximation. Therefore, Melanie approximates the standard error of all sample means (n = 45) to be
[latex]s/\sqrt{n} = 3.2/\sqrt{45}=0.48[/latex]
Now she can assess how far away her sample is from the claimed mean in terms of standard errors. That is, she can compute the t-score of her sample mean.
T = [latex]\frac{statistic-parameter}{standarderror} = \frac{\bar{x}-\mu}{s/\sqrt{n}}=\frac{13.5-12}{0.48}[/latex]=3.14
The sample mean for Melanie’s random sample is approximately 3.14 standard errors above the overall mean of 12. We know from previous experience that a sample mean this far above µ is very unlikely. With a t-score this large, the P-value is very small. We use a simulation of the t-model for 44 degrees of freedom to verify this.
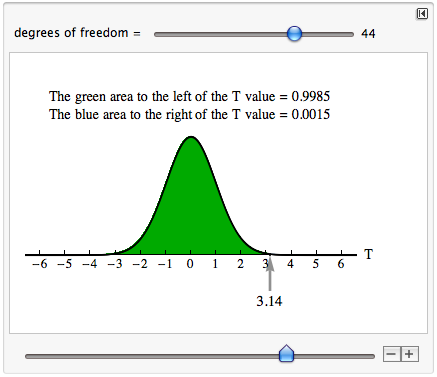
We want the probability that the sample mean is greater than 13.5. This corresponds to the probability that T is greater than 3.14. The P-value is 0.0015.
Step 4: State a conclusion.
Here the logic is the same as for other hypothesis tests. We use the P-value to make a decision. The P-value helps us determine if the difference we see between the data and the hypothesized value of µ is statistically significant or due to chance. One of two outcomes can occur:
- One possibility is that results similar to the actual sample are extremely unlikely. This means the data does not fit with results from random samples selected from the population described by the null hypothesis. In this case, it is unlikely that the data came from this population. The probability as measured by the P-value is small, so we view this as strong evidence against the null hypothesis. We reject the null hypothesis in favor of the alternative hypothesis.
- The other possibility is that results similar to the actual sample are fairly likely (not unusual). This means the data fits with typical results from random samples selected from the population described by the null hypothesis. The probability as measured by the P-value is large. In this case, we do not have evidence against the null hypothesis, so we cannot reject it in favor of the alternative hypothesis.
Melanie’s data is very unlikely if µ = 12. The probability is essentially zero (P-value = 0.0015). This means we will rarely see sample means greater than 13.5 if µ = 12. So we reject the null and accept the alternative hypothesis. In other words, this sample provides strong evidence that CPG has overstated the speed of its data download capability.
The following activities give you an opportunity to practice parts of the hypothesis testing process for a population mean. Later you will have the opportunity to practice the hypothesis test from start to finish.
Try It
For the following scenarios, give the null and alternative hypotheses and state in words what µ represents in your hypotheses. A good definition of µ describes both the variable and the population.
Comment
In the previous example, Melanie did not state a significance level for her test. If she had, the logic is the same as we used for hypothesis tests in Modules 8 and 9. To come to a conclusion about H0, we compare the P-value to the significance level α.
- If P ≤ α, we reject H0. We conclude there is significant evidence in favor of Ha.
- If P > α, we fail to reject H0. We conclude the sample does not provide significant evidence in favor of Ha.
Try It
Use this simulation when needed to answer questions below.
Try It
Try It
- Concepts in Statistics. Provided by: Open Learning Initiative. Located at: http://oli.cmu.edu. License: CC BY: Attribution
